We may not have flying cars but we do have incredible information technology. We’re mismeasuring the huge benefits it is bringing.
Every day, most of what I do in work and play was impossible 30 years ago.
The same probably applies to you, along with hundreds of millions of other people around the world. For many of us, life now revolves arounds technologies that were unimaginable only a generation ago.

Subscribe for $100 to receive six beautiful issues per year.
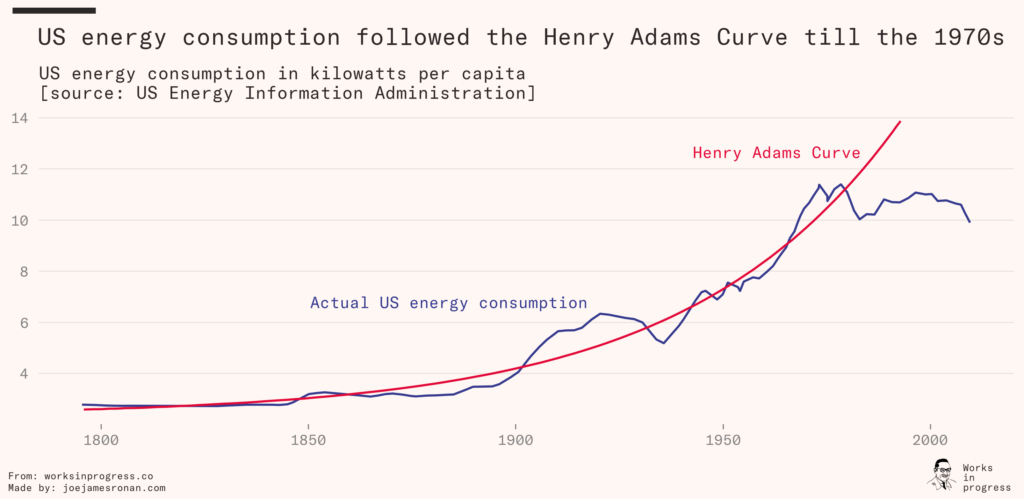
Yet, oddly, this era has coincided with slower growth on conventional measures, as J. Storrs Hall points out in Where Is My Flying Car? GDP growth, productivity growth, and wage growth have all slowed down. Energy output per capita has flatlined, ending a long streak of exponential growth that began with the industrial revolution. While much of today’s technology wasn’t imaginable 50 years ago, many of the other technological advances that were depicted in science fiction and expected to appear never came – including flying cars.
Reconciling this period of apparently slow growth with the technological leaps we’ve obviously made is not a new concern. While we likely have seen slowdowns in many areas of economic progress, it’s also plausible that normal economic metrics are unusually bad at measuring the output of the sorts of technologies that are now taking us forward.
Indeed, we may be seeing the opposite of stagnation, in the aggregate, and the areas we’ve made progress in could be accelerators for future growth. This is because our success relies upon cumulative culture: the accumulation and dissemination of the cultural knowledge that underpins our success as a species. Advances in information technology could act as force multipliers for advances in other areas, just as the invention of writing and the printing press revolutionized almost every area of society. General-purpose technologies like these sometimes take a long while to make their full effects felt. But, considering all the ways that information technology is already beginning to change society, the charge of stagnation begins to seem implausible.
Hall argues that stagnation can be seen in stifling regulations that have grounded attempts to develop flying cars; in technologies such as nanomachines that promised abundance but never materialized; and in wages, purchasing power, and GDP, where growth has slowed over past decades. As he presents it, stagnation is everywhere, even the defining feature of our society.
And yet we haven’t seen stagnation in our methods of banking, purchasing, relaxing, planning, dating, route finding, communicating, cooking, eating takeout, using taxis, writing, publishing, reading, watching, learning, listening to music, exploring obsessions, reading scientific literature, completing classwork, sharing research, or our ability to put Monty Python’s ‘What have the Romans done for us’ clip on a 10-hour loop as a sleeping aid (after years of lying awake plagued by anxious thoughts of the slow demise of civilization).
But still: Hall’s numbers do imply stagnation.
What’s going on here? How can so much of our daily life change, improve on multiple dimensions across nearly every activity, and yet classic measures of progress show those very same decades as ones of slowdown? How can we go from not having smartphones to using them for about a quarter of our waking hours, and yet see the digital economy as only being worth around five percent of our overall economy?
Looking in the wrong direction
A core problem is a focus on gross domestic product (GDP) as an indicator of progress. GDP is supposed to tell us how much production is going on in a country. However, if the measure only tracked the amount of money changing hands, it would simply measure the amount of money in the economy. Printing money would appear to be true growth.
Since we want to measure real production with GDP, we have to account for inflation – changes in the price level overall. To do that, we have to account for quality improvements at the same time. The products we buy, especially today, are not just undifferentiated widgets or bushels of wheat. An iPhone 13 is worth a lot more to most people than an iPhone 3G or – dare I say it – a Nokia 3310.
This is where problems creep in. How do we measure the quality of different mobile phones? Statistics bodies have tussled with this question, and they do attempt to do quality adjustments (known as hedonic adjustments). Ultimately, we are trying to work out how much welfare the products in question give people. For TVs, for example, stats bureaus like the US Bureau of Labor Statistics might include the increased benefits of TV screen size, internet connectivity, higher resolution, and so on and weigh that against the price. Statisticians build a model of the value of various attributes of a product, tracking the prices of different models year by year. They use this model to judge the value of quality improvements in new TVs, and if their price goes down 10 percent, but estimated quality goes up 10 percent as well, they say that prices – quality-adjusted prices – have fallen around 20 percent. For TVs, this method probably does account for most of the benefits fairly well, but this is not true in other areas.
Famously, GDP misses household production: If you decide to fire your cleaner and start cleaning your house yourself, GDP will fall by the full amount of their pay, but in fact output – the thing GDP is supposed to measure – may be nearly identical to before.
GDP also has serious trouble with patient welfare in health care. Cataract operations once required a week of recovery time in hospital. Medical innovation means operation and recovery times now take less than a day, and overnight stays aren’t required – but this advance doesn’t get represented in GDP unless the cost increases. A single night in hospital costs double the price of the whole operation, so this innovation actually resulted in a drop in cataract-related GDP.
GDP also breaks down as a measure of progress where there are spillovers – effects that aren’t included in purchasing decisions but that have notable effects on welfare. Generally this is negligible, because the number of spillovers doesn’t change dramatically every year, but sometimes the trajectory changes notably. London pollution was once so bad that a single year’s winter fog killed 4,000 people. The 1956 Clean Air Act cut sulfur pollution levels by 85 percent, at the cost of removing convenient and cheap options for heating and power. There have been hundreds of such environmental policies around the world, each individually reducing output by making it more expensive or impossible, but many also delivering substantial and unmeasured health benefits.
GDP also has serious trouble dealing with new, completely unpaid technologies, and improvements in them. To take a single example, music streaming services like Spotify mean that consumers around the world constantly have access to almost all the music that was available in 2000, when money spent on recorded music peaked, but also have access to vast libraries of recently made music, enjoyed at much greater convenience. Yet GDP estimates don’t attempt to account for this enormous expansion in consumers’ ability to constantly consume a greater selection of chosen content, once paid for on a piecemeal basis, so this technological improvement manifests as a drop in GDP. Official bureaus haven’t tried to make hedonic adjustments to account for improvements in access to recorded music.
Between 2011 and 2022, global coverage of 4G increased from 5 percent to 80 percent of the world’s population and over 5.5 billion people became smartphone owners. In the rapid process of global internet rollout, billions of people around the world are gaining access to a wealth of freely accessible online resources. The world’s most comprehensive encyclopedia, Wikipedia, is obviously among them: its inferior predecessor, the Encyclopedia Britannica, cost $1,400. Almost 20,000 university courses, each one costing thousands of dollars to the students attending live, can be accessed on your phone – and your phone can also play all the films, TV, and music you get on streaming services, at a fraction of the previous price. Endless video entertainment and education is available for free on Youtube – a single two-hour recording like a film used to cost about $15. With a smartphone, you have a way to instantly communicate over vast distances via text, audio, and video, previously impossible without your own TV studio. Most of this value has not been included in our hedonic adjustments, and hasn’t shown up in GDP.
GDP works well as a measure of progress wherever prices are a decent proxy for value. When this is not true, and improvements occur without measurable price or output effects, it stops being a good measure of the kind of economic progress that matters. If those sectors become a sufficiently important part of our lives, GDP may stop being a good measure of economic progress overall. It struggles to see progress we don’t pay for.
Where else can we look?
To address the issues involved in measuring health care output, governments, health care authorities, and economists tend to use direct measures of health care impact, such as quality- or disability-adjusted life years (QALYs and DALYs). A year in perfect health is taken as 1, and then adjusted down to account for the experienced cost of a health condition. A year with lower back pain might count as around 0.6, a year with daily heartburn as 0.8. These adjustments are usually calculated by asking people hypothetical questions such as, ‘Would you prefer to live an extra 30 years in perfect health or 50 years with a given disability?’ The value of a given health intervention can then be calculated, and considered for cost-effectiveness – if a treatment fixes lower back pain, it’s worth twice as much as a treatment fixing daily heartburn. These subjective valuations on the welfare cost of disease then allow health care bodies like the National Institute for Health and Care Excellence (NICE) to formulate policies on which medical interventions are worth paying for. The QALY value of such interventions isn’t incorporated into GDP – we simply measure the actual cost, whilst collectively agreeing that progress in health care is not well represented in GDP. The same is true for the environment – and we should probably recognize that something similar is happening in the digital sphere.
Increasingly, economists are coming up with ways to estimate the value of the intangible goods that form such an important part of modern lives.
According to one influential study by economist Chad Syverson, productivity has fallen so far since 2004 that the cumulative impact amounts to over $9,000 per capita in the USA. According to Syverson this is the gap that understatement or mismeasurement of digital tech would have to fill to challenge the stagnation story. Is such a missing figure feasible?
Erik Brynjolfsson and his colleagues have attempted to estimate the real value of the many cheap or free digital services now available using massive online experiments. The authors asked respondents whether they would give up a digital service (email, maps, search, socials, etc.) in exchange for a particular amount of money. Different participants were offered anything from a few dollars to tens of thousands. To stop the choice from being purely hypothetical, 1 in every 20 participants was given the option to take the trade they opted for, with the authors using a monitoring service to check their online status.
Over many participants, this allowed them to calculate the average amount it would take to convince someone to give up the service – implying its average value to the consumer. They found search engines were the most valued category of digital goods ($17,530 per person per year), followed by email ($8,414) and digital maps ($3,648). These are all currently provided for free. Streaming services such as Youtube and Netflix are valued at $1,173, about 10 times what consumers pay. E-commerce, social media, music, and instant messaging sum to another $1,400. To me, these figures seem plausible (really, I would pay more for search engines and email, because my career relies on them).
Another experiment locked apps on Dutch subjects’ smartphones, but also gave them a sealed letter that they could open to regain access. They were told a randomly assigned euro payout that they could keep if the seal was not broken during the month of the study. For WhatsApp, the most popular service, no one accepted €1 not to use the app, and the median subject needed to be paid over €500 per month to resist the temptation of regaining access.
The centrality of computers and the internet to our daily lives is obvious – I think the case against stagnation, at least in the digital era, is obvious too. This is not to say that growth hasn’t slowed in other important areas (it undoubtedly has) or that we shouldn’t be sad about the nonexistence of technologies that were expected but never materialized (we should). But if we emphasize stagnation as defining our era whilst overlooking unmeasured advances in IT, we clearly miss a major dimension of recent human advancement.
What’s more, digital technology is not just a convenient new way of delivering us garden-variety twentieth-century intangible goods but at lower cost. It is also a general-purpose technology for basically everything else. General-purpose technologies often take a long time for their full effects to be felt, and surveying some of the technologies we are on the cusp of may make us feel – contra Storrs Hall – quite optimistic about our future path.
The Pivot of Progress
Three hundred years ago Carl Linnaeus named us Homo sapiens – the knowing humans. The founding father of natural taxonomy picked out the characteristic of sapiens to define us – deciding that this capacity for knowledge is our pivotal attribute (although given his occupation of classifying thousands upon thousands of animals and plants, we can assume some bias).
Today, a leading theory of what makes sapiens so special is only a slight tweak on Linnaeus’s. Evolutionary anthropologists now highlight our capacity to develop culture and thus advance by cultural evolution. Basically, our ability to copy and build on successful cultural traits in others without having to evolve by genetics alone. Leading evolutionary biologist Joseph Henrich titled his book on the topic The Secret of Our Success.
Of particular importance to the progress of cultural evolution is cumulative culture:
“The human capacity to build on the cultural behaviors of one’s predecessors, allowing increases in cultural complexity to occur such that many of our cultural artifacts, products and technologies have progressed beyond what a single individual could invent alone.”
Key evidence that we should single out cumulative culture as making us special is in comparative research: Essentially every other species has to innovate individual by individual, with occasional minor instances of teaching and learning. This even distinguishes us from apes, which at young ages are better problem solvers than young humans, but far worse copiers. Other species rely more upon natural biological and genetic capacity to evolve their behaviors; human activities can progress remarkably from generation to generation without any relevant genetic evolution at all.
Every tool, technology, law, and science relies upon cumulative culture. Without the capacity to learn, innovate, and teach, you can have no meaningful civilization or growth. We might be distracted by inventions of fire, agriculture, stone tools, or the plow as comparable contenders to explain the rise of humanity; but such inventions could only help a single group for a single generation if they had been discovered but not communicated. The pivotal biological capacity that humans developed, perhaps one million years ago according to Henrich, was to accumulate cultural information.
The central communication technology of the last 2,000 years has been writing. The permanence of written information allowed laws to be codified, trade and property to be accounted for, and governance to be formalized. In the sixth century, Italy produced two thirds of all the books in Europe – this declined as the Roman Empire collapsed. For centuries literacy and writing were primarily necessities for merchants, politicians, and clergy to maintain civil life.
The printing press took writing’s potential and ramped up production. Invented around 1440, the technology was adopted startlingly quickly – within a single generation, printing presses had spread to the corners of Western Europe, and the price of books had been cut by two thirds or more. In the following centuries book production ballooned. In the year 1550, three million books were produced in Europe – as many as in the whole fourteenth century. In the 1800s, over a billion books were printed in Europe. The cultural changes happening in this period relied in large part upon this greater capacity to communicate – the Protestant Reformation, the emergence of early modern science and Enlightenment philosophy, the growth of universities, political democratization, and, ultimately, the industrial revolution relied upon printed paper produced with greater efficiency and lower cost.
Framing human progress as dependent at every stage on the transference of information, the advance the internet represents becomes truly radical. Recent decades have seen us power up our capacity to deal with information – to receive it, store it, analyze it, and innovate upon it– and then share it. Every cultural artifact relies upon that capacity. What was done on wetware for a million years, and then on paper for a few thousand, is now being done via light.
Empowered science
Consider the centrality of effectively accumulating information in science. To move science forward, researchers have to find out what is known and unknown, build upon it, and relay their progress back to the field. This epitomizes cumulative culture. In a paper-bound world the best method of doing this was to regularly read and report one’s research through subject-specific periodical publications – journals, delivered to a university department by mail. Indeed, really the only way a scientist could work was by subscribing and contributing to a few such journals. However, this system imposed bottlenecks on scientific progress, especially in length of reports and distribution speed.
What’s more, the growing size of a scientific field relying upon a journal publication system can impede progress, as systems to filter and integrate new works become inefficient. The size of a field becomes mountainous, which tends to ossify canon, as established canon becomes the only way to navigate gigantic fields spread across physical journal articles. This makes new ideas less likely to receive traction. The more a field grows, the more novel developments fail to be heard and sufficiently integrated.
Today, the system of scientific publication via journal articles persists, although most drafts, reviews, and published journals are no longer circulated in print. Many papers are not even cited once, and most scientists only regularly browse and contribute to a couple of subject-specific journals. There are more scientists (8.8 million at UNESCO’s latest count) doing more research than ever before – and the amount of researchers and research published continues to double roughly every 15 years. But the methods of scientific information communication have kept the same basic format of journal articles, despite the potential that technology opens up for change.
The recent rise of preprint servers and extensive supplementary materials allows modern scientists to communicate more of their work to the community, but these changes exist to circumvent various restrictions that journals have imported from the paper-bound days: word limits, an opaque peer-review process, no updating after publication, and high costs to purchase or publish. Once, these were necessary constraints of sending physical pieces of paper around the scientific community. They are maintained despite journals now being distributed via machines that could enable open peer-review, instant updating, and near-zero distribution or formatting costs, and that contain unlimited depth. Even preprints don’t take full advantage of these capacities: they are often shared as PDFs, keeping the structure and approximate size of journal articles, and are not as easily modified or updated as online resources such as Github.
The scientific community could look to how well gamers have used modern tools to make sure speedrunning records are accurate: videos of runs are posted online, reviewer comments are public and face democratic votes, and critics use probability theory models to judge the plausibility of results. One step in that direction is found in Jupyter notebooks, which allow scientists to provide their full data and code in such a way that anyone—even someone who isn’t familiar with the programming language being used—can rerun the analysis and get the same results.
Journals are not the only area where we can speculate about huge improvements due to digital technology – and those possibilities are already beginning to become reality. Consortiums of thousands of scientists and hundreds of thousands of individuals contribute to genetic databases: A leading example is the UK Biobank, which has detailed genetic data on half a million volunteers, linked to electronic health records; questionnaires on diet, cognitive function, and mental health; and all sorts of other health-related tests. They aim to soon have brain, heart, and full-body imaging on 100,000 individuals. Researchers with ideas about new tests to run on the volunteers are encouraged to reach out to the organizers. They are already helping us spot dementia early, understand the fundamental structure of the heart in a way that was previously impossible, identify risk factors for the diseases that kill the most people, and much more. During the first year of the Covid-19 pandemic, 700 sets of researchers used the data set.
This scale and depth of data collection and integration was essentially impossible 30 years ago, especially in data- and compute-hungry fields like genetics. Now it’s available at low cost to researchers around the world. Such giant data sets include larger numbers of rare conditions and a more diverse sample. Promising drug development targets are already being identified by deeper and richer genetic databases like the Biobank, especially by sequencing the exome, the 1.5 percent of the genome that is exons, which code for proteins. Digital records also make it easy to update data, and query it with new research questions – without having to do another entire study.
Consumer and industry data collection dwarfs these academic efforts. The company 23andMe has genetic data on over 12 million worldwide customers, 80 percent of whom have consented to participate in research (myself included). There are 86 million monthly users of health and fitness apps in the USA alone. A single exercise tracking app, Strava, has 95 million global active users and registered two billion activities in 2021, with over 32 billion kilometers of activity tracked by GPS. This data can be used for anything from understanding runners’ motivation to designing transportation infrastructure.
Female reproductive health apps are another area of giant growth: Period tracking apps have over 50 million regular users, and data collected from them have revealed greater than expected variation in cycle duration and ovulation day. Such data could provide insight into how women’s bodies’ renormalize after ceasing to take the pill, problems with PMS and period pains – and avenues to therapy. Previous studies of menstrual cycles contained many fewer individuals – studies in this meta-analysis had an average of 88 participants – and cost tens, if not hundreds, of thousands of dollars to run.
Information to change the world
More speculatively, our new technological capacities might be bringing us to the brink of revolutionary new solutions for huge social problems. Current mental health treatment is notoriously inconsistent. Psychiatric pharmaceuticals have unpredictable effects. Individuals differ massively in their experience of benefits and side effects, but few useful predictive heuristics are available, leading psychiatrists to cycle medications or use cocktails of drugs concurrently until they find one or a combination that works for the individual. Big data and machine learning algorithms offer a new opportunity to gain a level of sufficiently detailed information to turn this art of prescribing into a science; and new companies enabling AI-driven clinical decision-making boast twice the prescribing response rate.
Advances in therapy may be even bigger. Psychotherapy has forever been a black box in terms of precise measurement. Unlike pharmaceuticals, which can be tested against placebo and standardized between practitioners, therapy depends on a fluid conversation between two unique individuals. Trends come and go, therapists are trained in various schools of thought, but comparisons between schools have revealed basically no differences between their efficacy (although there are exceptions; exposure therapy being one of them). Developments in AI are now being used to analyze tens of thousands of hours of spoken therapy to improve training, whilst chat logs of online therapy can be scraped and analyzed, and theoretically automated. The race is on to train the ultimate AI therapist. The ideal AI therapist might just be a realistic human interlocutor, using techniques from cognitive behavioral therapy, but if the service can be provided at a significantly reduced cost, access could be increased and mental health issues more widely and successfully intervened in, and at an earlier point.
The burden of mental health problems is huge – between 20 and 50 percent of us will be diagnosable with a mental disorder in our lifetime. Digitized therapy won’t solve mental health problems entirely, of course – building therapeutic human relationships matters in some cases, and various mental health problems are related to difficult life circumstances, probably resisting treatment that doesn’t rectify the environmental factor. However, for those cases where what matters are certain words a person needs to hear or read – some kind of instruction, affirmation, direction, or information that may drive their thoughts and behaviors into a healthier place – the sorts of newly available big data, deep-learning approaches could provide reliably superior words or videos to the struggling person.
Mental health apps such as Calm and Youtube videos for motivation or insomnia are already serving this purpose, despite their limitations – comments sections are filled with people thanking content creators for changing their life. For now, the Youtube algorithm does the job of sorting out the best sleep or motivation videos, informed by likes, comments, and play counts – users have found a way to help one another, for free, on a platform never designed to improve mental well-being. As insurance companies and health services steadily rely more on digital options and automation, we should expect this capacity to help to bloom.
Mental health is only one area of health care ripe for rapid progress – our new IT-enabled power to integrate information of multiple genetic, epidemiological, and environmental factors may similarly allow improved treatment of complex diseases such as cancer, dementia, and diabetes, and improve predictive capacity and early diagnosis and intervention (without mentioning the improved efficacy of health care systems that can use electronic health records). Our descendents will surely be baffled that in 2022 we had been using smartphones for entertainment for over a decade but hardly started tapping their potential as devices for personalized health recording and advice.
Beyond health care, similarly transformative possibilities are opening for basic research: In the last 10 years hundreds of citizen science projects have begun, enabling computer-connected individuals to contribute to research across scientific fields from astronomy to ornithology. Cornell University’s Ebird program allows birders to keep Pokédex-style checklists of birds they have seen. Merlin (which has over one million users), also from Cornell, allows people to identify bird types from photographs and birdsong, using AI pattern matching, trained on the gigantic data set that birders are entering into Ebird.
Billions of individuals can contribute to the same database. Software can be used to discern patterns beyond human comprehension. Previously unimaginable quality and quantity of recording equipment exists in every pocket and home. The time span between data being collected and shared can be seconds rather than months, and researchers can report and track every small step of an experiment and analysis, release their code and the data set, and preregister their study to prove that they haven’t p-hacked. The capacity for human comprehension has probably not changed, but the capacity for us to organize, synthesize, and depict information has. This is anything but stagnation.
E-epilogue
Storrs Hall invokes the dreams of 1960s science fiction: flying cars, nanomachines that could rebuild the infrastructure of America in weeks, moon bases, and interstellar fleets. Those dreams did not come to pass – we never developed the technology to make them work.
What, though, could the twenty-first century’s futurists dream of? Perhaps an education system where every child has access to the world’s most interesting and important educational materials, is given a syllabus molded around their individual talents, and has their daily lessons designed based on evidence of their personal progress. Perhaps a justice system where rapists and robbers are reliably caught because every crime witnessed can be recorded, every token of money tracked, every person and valuable item geolocated. Perhaps today’s futurist might dream of massively participatory systems of government where every citizen can easily have their say on every local, regional, and national law and regulation, and every publicly funded activity can be made completely transparent, reducing inefficiency and preventing corruption and waste.
There is something different about these dreams, in comparison to twentieth-century science fiction of the type Storrs Hall was inspired by: All of these twenty-first-century dreams are technically achievable right now. They require only a modicum of software development and a bit of existing hardware distribution (plus, less easily, the necessary political and institutional vision). We don’t have to wait for some technological development of supersonic, supersafe flying cars, nuclear fusion, or nanomachines. We don’t even need to wait for artificial general intelligence. The capacity to vastly improve critical elements of our culture already sits in our hands; we only need to decide on implementation.
One of Storrs Hall’s yearnings is for ‘the journeys we would have made’ with flying cars – the missed opportunity of certain journeys only open to us when our Ford can fly. I suggest an equivalent way to frame the progress represented by the digital revolution: Instead of thinking of the journeys we couldn’t make without flying cars, think of the information we couldn’t share without the internet.