Breakthroughs in artificial intelligence are forcing skeptics to eat their words. We should take its risks seriously too.
Artificial intelligence has advanced at an incredibly rapid pace in the last few years. As these systems get more powerful, more and more people are beginning to worry about them not acting how they should – not necessarily because of sentience or malice, but because they may try to achieve their goals in ways that cause harms they haven’t been designed to avoid. ‘Humans misusing technology is as old as dirt,’ said Scott Alexander, ‘technology misusing itself is a novel problem.’ You might get exactly what you asked for, but not what you really wanted.
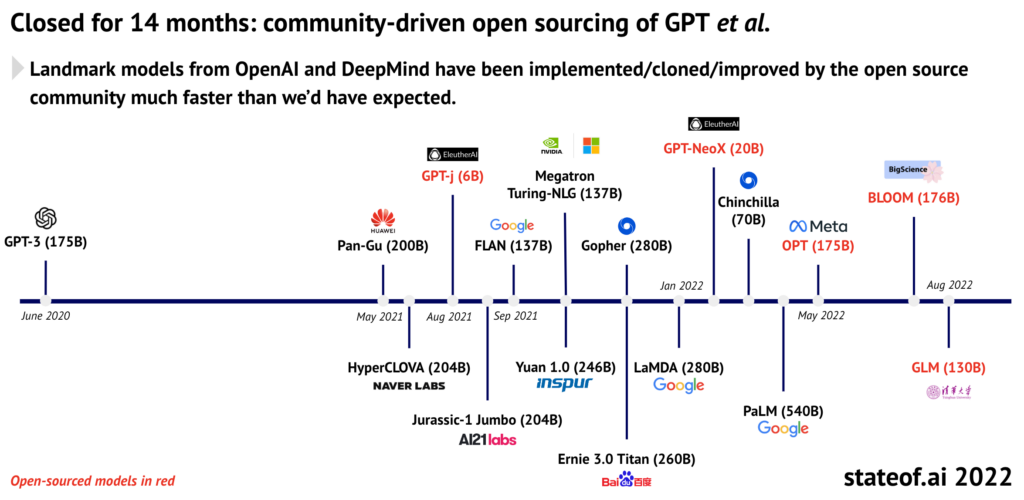
The philosopher Nick Bostrom popularized this line of thought in his book Superintelligence, published in 2014. Back then, the risks of AI were a niche concern: The idea of AI causing large-scale harm seemed far-fetched at best, particularly given how immature and feeble most examples of AI were at the time. But the years since then have changed everything: AI has improved dramatically, and AI safety research along with it.

Subscribe for $100 to receive six beautiful issues per year.
Stuart Russell, one of the pioneers of machine learning, gives the hypothetical example of an AI tasked with combating the acidification of the oceans. To do this, the machine develops a catalyst that enables a rapid chemical reaction between ocean and atmosphere, restoring the oceans’ pH levels. However, in the process doing so, it also depletes most of the atmosphere’s oxygen, leaving humans and animals to die from asphyxiation.
Of course, no such system exists yet; but the dynamics described – rapid optimization with unintended and undesirable consequences – do. Few people need to be convinced that the unrestrained pursuit of any goal, without consideration of the costs involved, can lead to significant harm.
Questions of AI safety – trying to understand and avoid these kinds of scenarios – are now central for some AI researchers. This article aims to show that recent technical advances lend credence to the view that AI is likely to become increasingly powerful over the next few decades, potentially even achieving a ‘general’ intelligence that resembles human abilities to think. It also aims to describe what AI safety research involves alongside this risk. It is worth noting that many other risks or harms from AI are not extensively detailed here, such as discrimination, fairness, and privacy: These are outside the scope of the piece, which is not to suggest that they’re not important as well – on the contrary.
The developments described in this piece are impressive technological steps that will, by themselves, make people’s lives better and suggest a path for AI that could be as revolutionary and positive for the world as the Industrial Revolution was. This technology could mean, for example, hundreds of new, effective drugs every year for the worst diseases discovered. It could mean improving on renewable and nuclear energy safety and efficiency so rapidly that we can solve climate change and reach energy abundance. It could mean new crop strains that help solve world hunger. It could also mean incredibly fun video games – including ones personalized to every player’s taste. But this technology comes with important risks too. Understanding and minimizing these does not need to mean – and must not be made to mean – missing out on the benefits of advanced AI.
How AI has evolved, from Superintelligence to today
Machine learning is a field of computing that uses algorithms and statistical models to build software that can improve its performance at specific tasks over time, using data to generate rules and trial and error to ‘learn’ which rules work and which don’t.
In the past decade, we’ve seen very fast progress in the field thanks to two techniques. The first is deep learning – this involves the use of artificial neural networks, which are algorithms modeled after a very much simplified structure of the human brain. The second is reinforcement learning, where a software ‘agent’ learns to interact with its environment in order to maximize a ‘reward’ that it has been programmed to seek. This is done by the agent taking actions that lead to the greatest reward over time and adjusting its behavior based on the feedback it receives.
Existing AI systems are narrow: They are designed for a single or tightly scoped purpose. The holy grail for AI researchers is to create an artificial general intelligence (AGI), where a single AI agent is able to understand and learn any task that a human being can. But why stop there? Since machines are not constrained by biology, it’s also plausible they could become significantly more intelligent or capable than any human (even if the nature of such intelligence is different from our own). For example, this could happen if an agent is asked to work on building a slightly smarter version of itself, which then builds a smarter version of itself, and so on. This would, obviously, be one of the most risky AIs to deal with, but non-general advanced AI can still cause problems too.
To better understand the concerns of AI safety researchers, we need to consider two things. First, why such a system might cause harm to human beings. Second, how fast we can expect such a system to be created. If progress and deployment is fast, then work on safety should at least be equally fast, whereas if we think creating general intelligence will take hundreds of years, then we have more time to solve the technical problems worrying safety researchers. While we can’t predict the future, we can observe how AI has progressed in the past decade, and get a better sense of where things might be heading.
Ten years ago, generating a photorealistic image or video from scratch, accurately predicting protein structures, rapidly detecting various forms of cancer, asking language models to summarize a book, and using intelligent robots in surgery were all virtually unthinkable. These applications, while still in early stages, are rapidly being used by cutting-edge companies and researchers. Advances like these are often discounted as not really being ‘intelligence’ – as the Australian roboticist Rodney Brooks has said, ‘Every time we figure out a piece of it, it stops being magical; we say, “Oh, that’s just a computation”’.
But while increases in performance and efficiency are hard to dismiss, there are of course also plenty of things we haven’t achieved yet that we’d hoped we would. We still don’t have fully self-driving cars after over a decade of promises that these were only a few years away. A medical chatbot based on the AI language software GPT-3 advised a mock patient to commit suicide. Even so, the rate of progress across the board seems faster than many would have predicted, and researchers increasingly think that artificial general intelligence is not only possible, but could happen in the next few decades. Let’s consider progress made in a selection of fields.
Games and simulated environments
The clearest case of improvements in AI is their ability to win at games once thought to require too much creative play for a machine to be able to beat the top human competitors. Board and video games have clear rules and success criteria, but often require continual learning and strategic adaptation, important components of intelligence.
When the supercomputer Deep Blue beat Garry Kasparov, the reigning world chess champion, in 1997, many of the techniques it used were relatively specific to chess. But Deep Blue relied on a combination of supercomputer processing power and specialized chess chips: It memorized a large data set of chess moves, and then determined possible moves and outcomes through a game tree search algorithm.
The game Go, in contrast, was much harder to tackle. With a 19-by-19 board, there are at least 361 legal starting moves. This presents billions of possible combinations in just the first four moves – far more in the process of a whole game than a model like Deep Blue could memorize and compute. As of 2012, AIs could only achieve the level of a strong amateur. But in 2016, the British AI firm DeepMind (owned by Alphabet) developed AlphaGo. The program independently trained itself to play Go through reinforcement learning rather than copying existing moves and data fed into it, as AIs like Deep Blue did.
Because reinforcement learning requires experimentation and trial and error, AlphaGo’s developers did not have to feed it knowledge specific to Go in the same way that IBM had to teach Deep Blue about standard chess openings. Not only was AlphaGo able to defeat the world Go champion in 2016, but professional Go player Michael Redmond even described some of AlphaGo’s moves as creative, unique, and brilliant. Equivalent techniques were subsequently used by more powerful models: While AlphaGo was initially trained on thousands of human amateur and professional games to learn how to play Go, AlphaGo Zero skips this step and learns to play simply by playing games against itself, starting from completely random play. A subsequent AI, Alphazero, needed zero human-provided data (not even a single amateur game) to make sense of, and fully master, the game of Go – albeit with gameplay very different to that of humans.
In chess and Go, the information you need about the state of play is on the board and in the rule book. But in other games, different players have different pieces of information. Poker, where players have different knowledge of their hands and, as a result, the cards available in the deck, and where their resulting behavior can reveal some of this knowledge to other players, is a good example. No-Limit Texas Hold‘em was seen as a particularly difficult challenge for AIs for a long time, because of the importance of reading the behavior of other players. But, by 2019, an AI system had demonstrated mastery of the game. In a 12-day session with over 10,000 hands, a poker bot called Pluribus defeated 15 top human players.
More recently, Meta announced that its Cicero agent convincingly negotiated with humans in plain English while playing an online version of the board game Diplomacy. This strategy game requires players to build trust and cooperate with each other, but also lie and backstab opportunistically in order to win. This AI had done more than pass a Turing test – an old (and arguably flawed) measure of an AI’s sophistication, based on whether it could speak with a human without the human realizing they were speaking to an AI. This AI was able to actively deceive and beat human beings without them knowing it was an AI they were dealing with.
This is particularly promising because lots of useful real-world applications of AI involve this kind of interaction with humans who don’t share the AI’s way of acting. A self-driving car should not assume that other drivers on the road are perfectly rational and going to behave optimally. If an AI like Cicero can strategize or bet about human behaviors on the road in the same way it can about their actions in Diplomacy or other games, taking into account humans’ flaws when deciding what to do next, it may be able to overcome some of the barriers that currently stop AIs from working effectively in public.
It’s worth noting, however, that depending on how it’s applied, this work can also be useful in the context of safety, for example by revealing how and when AIs are more likely to cooperate or defect.
Language synthesis and conversation
Historically, it has been impossible to have ‘human’-feeling conversations with artificial intelligences. For a long time, basic conversation bots tended to rely heavily on preprogrammed, hard-coded responses and regurgitations of tweaks to users’ questions, like the Eliza programme released in 1966. Other approaches used Markov models to look at the last few words in a sentence to predict which word was most likely to come next.
But this lacked any meaningful semblance of understanding, or even the ability to remember how the sentence began. A conversation is a much less neatly defined problem than a game like chess or even poker: We expect other people to be able to come up with intelligent responses to sentences that they may have never heard before, which requires them to quickly interpret their conversation partner’s meaning, the wider context, inferences, and assumptions. Good luck capturing all that with simple if-then statements.
.jpg){kind=link}
This changed in 2017, when Google Brain published a new deep learning approach: the Transformer. Open AI subsequently used the Transformer architecture to create its GPT (Generative Pre-Trained Transformer) models, which were trained on an enormous corpus of text sourced from across the internet. GPT used massively more computing power – or, as it’s referred to in the field, compute – than previous models and proved far more capable at maintaining a natural conversation with the user. Now, given a short prompt, GPT-3, the latest version of the model, can write text that seems like it was written by a human. It can write poetry and even code. GPT-4 appears to be significantly more impressive. Google’s recent 540-billion parameter Transformer language model can even engage in reasoning to reach an answer based on just two examples of logical reasoning:
| Input: Q: Sean was in a rush to get home, but the light turned yellow and he was forced to do what? Answer Choices: (a) take time (b) dawdle (c) go slowly (d) ocean (e) slow down. Answer: The answer is (e) slow down. |
Translating text and audio poses a similar problem for AI. Until the early 1990s, this could only be done by skilled humans who were fluent in multiple languages. But, while fairly crude translation software (that often simply translated word for word without using context to determine meaning) has existed for decades, in recent years we have seen impressive improvements in machine translation – particularly when leveraging artificial neural networks. For casual use, Google Translate or DeepL are good enough for most situations. And thanks to new AI techniques, like improvements in model architecture and training and improved treatment of noise in data sets, it’s now possible to translate languages lacking copious amounts of training data, such as Yoruba or Malayalam.
There are of course still important limitations to these models. Machine learning creates models that infer patterns from large historical data sets, or in other words, models learn whatever data they are fed. The ‘garbage in, garbage out’ adage proves particularly true in this case: Microsoft’s infamous Tay assistant famously began using swear words and racial slurs after learning from malicious users online, and even GPT-3 remains heavily biased in certain contexts (for example, associating Muslims with terrorism and violence).
But even when trained with carefully curated data sets, language models are known to ‘hallucinate’ or make things up: Researchers scrutinized Meta’s Galactica model, trained on a large corpus of scientific papers to distill scientific knowledge, only to discover that it would recommend wrong and occasionally dangerous answers that sounded correct and authoritative. This is not too dissimilar to people who ‘sort of’ know what they are talking about, without truly understanding it. Combine this with Cicero’s capability to deceive (as seen in the board game Diplomacy), and you start to get a sense of why some people are worried.
Media and multitasking
The ability to use machine learning to generate faces and illustrations is also evolving at a rapid clip. Open AI’s recently released Dall-E 2 algorithm can create original, realistic images and art from a simple text description, as have many new competitors. University of Illinois professor Ted Underwood compared the results of the same prompt – ‘the towers of a fairytale castle rise above a tangled hedge of briars and roses’ – in 2021 versus early 2022, and then again in late 2022 (with a slightly different prompt). The differences are striking:


Even in the space of a couple of months, the improvements are stark. Around the time Stable Diffusion was released, in May 2022, I predicted that in about a year’s time we would have machine-generated videos; it actually took two months to get 3D animations and video generation capabilities. Text-to-video models can now produce long, high-definition videos from a simple text prompt.
AIs are also getting better at ‘grasping’ common sense and making more effective use of contextual information – in the 1980s, AI researchers wrongly believed this would require writing down all rules, scenarios, and possibilities manually. In a recent Google AI study, a robot was used to act as a natural language-processing model’s ‘hands and eyes’, with the language model helping the robot to understand and execute long, abstract instructions. If you asked a language model alone, ‘I spilled something, can you help?’ it might give you an answer such as, ‘I can vacuum that up for you’, despite this not being effectively true or possible. But combined with the robot’s contextual assessment, the language model is then able to both respond with a context-aware output (‘I would: 1. find a sponge, 2. pick up the sponge, 3. bring it to you, 4. done.’) and execute this sequence on the robot in a real kitchen.
This is important because ‘common sense’ has so far eluded many machine learning applications. A language model might compose realistically implausible sentences like “Dogs love playing Frisbee together’, which might be acceptable in a children’s book, but not in a news article. Models often struggle to get the broader context right. But here, too, progress is evident: A recent paper on Socratic Models demonstrates how visual language models and traditional language models, working together, can achieve a level of ‘common sense’ across domains. This allows the AI to perform multimodal tasks like summarizing a video as a short story, then answering questions about it with no fine-tuning needed and without necessarily needing large training sets. Another example is the Pathways Language Model (Palm), which can distinguish cause and effect, ‘understand’ conceptual combinations in appropriate contexts, and even guess a movie based on emoji (correctly selecting Wall-E in a list of possible answers for ‘🤖🪳🌱🌎’).
From general purpose algorithms . . .
While there’s been clear progress on many fronts, it is important not to lose sight of limitations too. As with language models, many other algorithms remain troublesome, and in certain contexts like facial recognition or emotion recognition, the opacity and unpredictability of machine learning systems remains a difficult problem to solve, and makes it difficult to rely on them in the real world.
Still, the astronomic growth of AI shows tangible results and rapid improvements. DeepMind recently announced the publication of Gato, the most general machine learning model to date. The types of tasks it can perform are much broader than other models we’ve seen so far. These include controlling a virtual body in a simulated environment, a number of vision- and language-related tasks like captioning images and videos, playing Atari, and some basic robotic tasks, like stacking blocks. This isn’t a collection of different AIs bolted together; this is a single system that has achieved this wide set of capabilities through adding in much more data and using much more compute and many more model parameters (other inputs and tweaks).
Artificial intelligence is also increasingly used to accelerate scientific research, in concert with human researchers. In October, DeepMind announced the discovery of a more efficient way to perform matrix multiplication (requiring fewer multiplications than known methods), beating a 50-year-old record. A couple of weeks later, this technique was further improved on by two Austrian mathematicians at Johannes Kepler University Linz. In the summer of 2022, DeepMind released AI-derived predictions for the structures for nearly all cataloged proteins known to science – over 200 million of them. Prior to that, only 0.1 percent of protein structures were discovered and the process of determining their 3D structure took months or years of laboratory work. Researchers were also recently able to decode visual stimuli using only a few paired fMRI-image annotations from brain recordings: In other words, an AI system was used to successfully retranscribe visual representations imaged in a human’s brain.

These developments demonstrate two things. First, we are almost certainly not on the cusp of an ‘AI winter’, as some researchers have been claiming for the last few years. If anything, cutting-edge research and progress in this space is accelerating, at least in some key respects. Second, we are getting increasingly powerful narrow AI systems, and some early signs of more generalized systems. So can we expect a true general AI – and, if so, when?
. . . To artificial general intelligence
One way of working out when we’ll get true humanlike artificial general intelligences is by asking experts. In one 2017 survey, around a quarter of respondents believed that we would create AGI within 20 years (i.e., by 2037), but another quarter thought it wouldn’t happen for at least 100. The leading lights of the field fall on the bullish side: Richard Sutton, a founding father of reinforcement learning, estimates a 50 percent probability of achieving transformative AI by 2040.
Other forecasting methodologies exist too. Some AI researchers believe that AIs that can use human brain levels of compute will also, then, achieve human brain levels of intelligence. Based on a forward projection of current trends, one estimate judged that there was a 50 percent chance we’d get to this point by 2055 – and this was more recently updated to 2040.
Who is right? Part of this gap depends on whether we can use relatively crude AIs, closer to the ones we have today, to build more sophisticated ones. Some researchers think it will be impossible to teach an AI to improve itself without getting past other bottlenecks. They argue that conceptual breakthroughs are still needed in domains like understanding human language, the human ability to learn cumulatively, figuring out the hierarchy in a set of ideas, doing ‘more with less’, and the ability to prioritize what to think about next.
But AIs are already improving themselves. It was recently done for the first time, with researchers successfully programming a model capable of autonomously editing its own source code to improve its performance. And this was not a fluke: Other researchers have shown that some large language models could self-improve rather than having to rely on humans fine-tuning the model. The success of ChatGPT, released in late November 2022, suggested that a language model could fix bugs in code provided to it, and even explain why it did it. If a non-general AI can improve itself, giving it capacity to further improve itself recursively, then we may see rapid improvements in short time spans.
Thanks to these advances increasing interest and investment in the field, AI research is accelerating: the Global Catastrophic Risk Institute’s 2020 report identified 72 active artificial general intelligence R&D projects spread across 37 countries, up from 45 projects in 30 countries in 2017. The number has surely risen even since then.
AI safety (and why we should care)
All these recent advances should make us open to the idea that a true artificial general intelligence is possible. Skeptics have repeatedly been proven wrong, and past benchmarks have successively been exceeded. And though most of the contributions AI technology has made to the world so far are positive, someday this might change.
As AI systems get smarter, more capable, and more interconnected, there could come a point beyond which understanding and evaluating them will be much more difficult, and will require new methods and techniques. In addition, their reckless or accidental deployment could also cause great harm as they pursue goals – even if those goals are ones we have set for them. A sufficiently capable agent could deceive us, having ‘learned’ that we would otherwise obstruct its pursuit of a goal we have set for it. Even destructive and malicious humans have rarely been dramatically smarter in all domains than the rest of us, and most have built-in biological and cultural reasons to care about others. An AI may not.
And as the rate of progress in the field increases, we have less and less time to make sure we are not accidentally building an AI that may backfire on us, and be too sophisticated for us to easily stop or control. The AI safety and governance field remains quite small compared to the amount of resources we spend on avoiding other harms. By way of comparison, food safety qualifications are taken by over 70,000 people every year in the UK alone.
But all this might seem academic without a clear understanding of how AIs are already reaching the goals we give them in unintended ways, along with what they might do next.
Black box systems, value alignment, and specification gaming
A sufficiently advanced AI pursuing its goals may well cause harm in trying to reach that objective. Indeed an advanced AI system will not be aware or cognizant it is causing damage – why would it?
Why not just program AIs to never harm humans, you might ask? Artificial intelligence sometimes works in mysterious ways. One well-known issue is that with neural networks, we don’t really know what individual ‘neurons’ (nodes in the neural network) are doing to generate a particular final output. In other words, we can see the result, but the inner workings remain a mystery – or at least not accessible with simple analysis. This already makes it difficult to understand even very basic outputs (why Dall-E generated this image), let alone verifying whether an AI is aligned and behaving as intended. Humans too are hardly explainable, but now we have a new class of agents to consider.
This complicates another behavioral quirk. Specification gaming (or reward hacking) happens when machine learning systems focus on the letter of whatever specification or objective they are given at the cost of the spirit of why it was given. When an AI is designed, we specify an objective that the algorithm should maximize – but, as described earlier, this could involve it doing a lot of stuff we didn’t mention that we don’t want it to do as well. This is related to the problem of scalable oversight: how do you provide feedback to AIs doing things you don’t fully understand in the first place?
One of the authors of the most popular AI text book in the world, Stuart Russell compares the challenge of defining an AI’s objective to the myth of King Midas – who didn’t actually want everything he touched to turn to gold. One research paper compares it to the case of Kelly the dolphin, who, upon learning that she would be rewarded for bringing trash to her handler, was observed stowing trash in a corner of her habitat and tearing off small pieces to maximize the number of fish she could earn. It’s easy to imagine how a similar dynamic might play out with a powerful AI that has been given simplistic or inaccurate values.
So far, we’ve seen only small-scale examples of our existing artificial intelligences going wrong, largely in situations where designers did not perfectly specify what they wanted.
In one case, OpenAI scientists trained a reinforcement learning system to play the simple Flash game Coast Runners, where the goal is to knock targets and finish the boat race as fast as possible to get the most points. Here the agent beat human players but did so in a completely unexpected way: The boat would drive in an infinite loop, timed perfectly to knock respawning targets, without ever finishing the race – despite catching on fire and crashing into other boats.
Researchers at Open AI found that even a variation of hide and seek could be gamed. Two classes of agents – hiders and seekers – were told to play the game: Seekers learned to run after hiders, and hiders learned to hide from them. The simulated environment contained boxes, but the programmers did not tell the hiders or the seekers to use them. Yet after 380 million games of hide and seek, the agents developed unintended behaviors and strategies (like using the boxes as forts and walls, or ‘surfing’ over them) that the researchers didn’t even know were possible – in a simulated environment they had designed themselves!
Surfing on boxes, while obviously not sinister behavior, does show the capacity of even current-day AIs for doing things outside the scope imagined by their designers. In a hide and seek game it hardly matters, but in the real world the scope for surprising behavior has more downside risks.
Goal misgeneralization
There are also other reasons why an AI might pursue incorrect goals, even if it was originally trained with a well-defined and expansive objective. In a simulated environment, an AI will appear to follow the correct goal: The observed behavior seems positive and generalizable outside a training run. Once it is deployed in a new environment, its capabilities may generalize well but its ‘understanding’ of the goal might not, even if the environments seem very similar to human eyes.
In one example, a simulated environment is created with keys and chests. The agent is given the goal to open chests, so it learns to collect keys to do so. This is tried in different environments, and the agent seems to always get it right: The developer can observe it doing the right thing. But it turns out that in these training setups, there were always more chests than keys. Once the agent was deployed in an environment with more keys than chests, the agent seemed instead to collect all the keys and disregard some chests. The misgeneralized goal had become collecting keys, despite the agent being initially trained to open chests.
This illustrates two things: First, context and changing environments matter greatly (e.g., the ratio of chests to keys), and can affect an objective even if that objective is correctly specified in the first place. Unlike simulated environments, the real world changes dramatically, unpredictably, and sometimes imperceptibly. In a real-life setting, an AI might have the correct specification but pursue it suboptimally until it finally finds the right balance.
Second, some scenarios may be particularly harmful and borderline catastrophic – like a drug that works well on test groups, but is lethal to some group of people it hasn’t been trialed on. Or imagine a self-driving car AI, trained in one state and deployed in another with slightly different road markings that, at night at a certain time of year, send the car’s navigation haywire. Differences in context that are invisible to humans and would never cause dramatic problems to us can be very bad for AIs that learn from cues that we barely understand.
Power-seeking behaviors
Another risk is that some advanced AI systems might seek some form of ‘power’ – that is, seek to be able to override human control over them – to achieve a prespecified objective. An AI-powered traffic management system with the objective to reduce congestion might seek the power to control the cars themselves.
One can imagine many scenarios in which this becomes a problem. An artificial intelligence might attempt to control or mislead people in order to attain certain objectives – including by preventing humans from stopping them. Indeed, some recent papers have experimentally justified such concerns: In some settings, it may be optimal for a reinforcement learning system to seek power by keeping a range of options available.
While science fiction has long imagined such scenarios, recent work shows that there are statistical tendencies in reinforcement learning that will encourage an AI to actively seek power, or to keep options open. Under certain conditions, a sufficiently intelligent system deployed in real-world conditions may well reproduce these power-seeking incentives.
A sufficiently powerful AI system may have incentives not to be shut off or stopped. It’s easy to imagine us ‘unplugging’ existing dumb systems – but if we do develop higher-than-human intelligence, it’s not clear that we will necessarily be able to unplug it. If an advanced AI judges that it cannot maximize its version of expected utility when it’s switched off, it may disagree with a human that tries to do so.
One strategy to address this issue involves carefully restructuring the goals of an AI to make it not mind being shut down – this is called interruptibility or corrigibility. The idea is to ensure that the AI cannot learn to prevent (or seek to prevent) being interrupted by the environment or a human operator. One suggestion in this vein is to give machines an appropriate level of uncertainty. This would help by creating more ‘humble’, uncertain agents with incentives to accept or seek out human oversight. Indeed, if an agent is uncertain about the utility associated with being shut down and treats the programmer’s actions as important/useful, then it may be less likely to resist being stopped or shut down. Another suggestion is to establish a dedicated input terminal to allow a human to edit an AI’s preferences and goals if necessary.
Toward value alignment
Maybe the ideal way of getting around all of these problems would be to achieve value alignment – giving advanced AIs roughly human values. Doing so is an ambitious task: the difficulty is not to identify ‘true’ moral principles for AI, but instead to identify fair principles for alignment that can account for widespread variation in people’s moral beliefs.
One way of doing this is to create systems that can infer human preferences from human behavior, then try to satisfy those preferences. Through observation and deduction, an AI might gradually come to understand what we want and don’t want. The second is to get the AI to properly understand human ‘natural’ language so we can tell it what to do with normal language and have it understand our nuance – which is what we already do to try to ‘align’ other humans with our goals.
We might also try to create ‘oracles’ – constrained AIs designed to answer questions without having goals or sub-goals that involve actually affecting or modifying the world. DeepMind recently found a way to train an AI to build a causal model of itself, helping it answer questions about why it is doing particular things. While this is early work, this could pave the way to getting models to eventually answer how they did particular things – normally we think true understanding of something comes with the ability to explain that thing.
When Alphazero plays chess it seems to pick up concepts that are very similar to human ones, even though none of these concepts were taught or encoded. It seems to be using ideas like ‘king safety’ or ‘material advantage’. If this happens more generally, it may make these black box systems a little less opaque. Perhaps if AIs can eventually grasp broader, more fundamental abstract concepts we could give them broader, more nuanced goals that are less prone to failure.
While many researchers are attempting to ‘future-proof’ advanced AIs that haven’t been built yet, some are focusing on understanding current AI systems and algorithms, on the assumption that future transformative AIs will be in some ways similar to these. After all, GPT-1 looks very much like GPT-3 – both are based on a similar architecture, but the latter is far more powerful and capable, thanks to the additional compute, parameters, and data available to it. So what changes as we add more compute and data? What kind of new things did these neural networks learn? How were new capabilities acquired? What techniques helped us better direct these models, and are these generalizable? This approach bets that we won’t need to uncover fundamentally new ideas about the nature of intelligence to solve alignment.
A Redwood Research team tackled this question by training a state-of-the-art language model on a huge corpus of fan fiction, largely about teenage spy Alex Rider – the database was so big they only got halfway through the A section as they were loading data in. Their goal was to improve the model to align it more closely with humans by giving it a better sense of nuance in language. This involved them trying to confuse the AI into saying that a given string of text was nonviolent (based on a naive analysis of the words) when any human could tell it was violent from context. When they observed bad results, this created teachable examples they could add to the algorithm in the future, improving the model.
At the Machine Intelligence Research Institute, researchers are exploring agent foundations – that is, trying to better understand the incentives superintelligent AIs might have to acquire resources like hardware, software, or energy. Part of their work looks to answer whether we can design agents that reason as if they are incomplete and potentially flawed in dangerous ways, and which are therefore amenable to correction – i.e., that come with a level of humility that reduces the chances they take irreversible actions or resist being stopped.
Similarly, researchers at the Alignment Research Center are looking into ways of building AIs of today’s sophistication with incentives to tell the truth, rather than whatever string of text they arbitrarily decide is worth spitting out. If they can do it with, for example, GPT-3, then perhaps they can use the same methods to do it for future, more transformative AIs.
Implications for policy and governance
In 2014, when Superintelligence was published, very few AI safety organizations and researchers engaged with policymakers, politicians, and the wider machinery of government. Even involvement with the private sector was limited and ad hoc, confining most of their ideas to niche journals and academic conferences.
Today, safety organizations lobby for a range of tweaks and interventions that they believe may help. But while research in AI governance and policy is growing, there is no overall plan for dealing with the biggest risks, and there are few clear proposals to tackle many of the potential future dangers described above.
The AI race and proliferation
One worry is a race dynamic, in which individual firms developing AI, or governments trying to encourage AI advances in their own countries, take excessive risks at the expense of safety in order to gain advantages for themselves.
These issues are a core part of existing AI policy efforts by those concerned with AI safety and governance, especially think tanks like the Future of Humanity Institute, the Center for Security and Emerging Technology, and the Centre for the Governance of AI. Cutthroat competition can undermine the prospect of restraint and caution. The problem is exacerbated by the possibility that there will be winner-takes-all dynamics, and getting to advanced AGI first is orders of magnitude more powerful than getting there second. The first organization to do so may be able to use their technology to gain a competitive edge in various industries, which could give them a significant economic advantage over their competitors.
No one has come up with any certain solutions yet, but there is growing work and research in these areas. One idea is that a broad agreement on some basic standards might be possible; cooperation is sometimes possible in a prisoner’s dilemma–like situation like this. Readers can decide for themselves whether the progress we have made on similar problems, like nuclear nonproliferation and reducing carbon emissions, is cause for optimism or pessimism.
Even a well-functioning and aligned AI can still do harm. which is why we may wish to be careful about rapid proliferation. While this ‘democratization’ is often positive, the ‘dual nature’ of these systems is frequently underappreciated: is model X used to improve camera doorbells, or is it used to identify and detain human rights activists?
Malicious actors could use artificial intelligence to fake video evidence (like in the BBC TV show The Capture), get into systems with speech synthesis or impersonation, hack autonomous vehicles and use them for physical attacks, or even exploit other AI systems by giving them false inputs:Researchers recently attacked the Stable Diffusion image generation model, injecting a backdoor in less than two minutes. By then inserting a single non-Latin character into the prompt, they were able to trigger the model to generate images of Rick Astley instead of boats on a lake. A similar backdoor in a traffic management system or a military AI system could do damage. AI safety researchers are increasingly getting as concerned with powerful AIs being weaponized and misused as they are with powerful agents causing havoc.
National policy, law, and governance
Some states have begun to act on these risks. The UK’s National AI Strategy is notable for its explicit recognition of artificial intelligence safety concerns, and the United Nations’s Our Common Agenda report explicitly calls for better management of catastrophic and existential risks. To address these challenges, some researchers have proposed the use of model cards and data sheets, which provide basic information about AI models, and auditing tools, which can be used to test and evaluate AI models without revealing intellectual property or trade secrets. These ideas may make it easier for AI firms to allow their models to be audited, potentially increasing transparency and trust in the AI industry. So far, agreeing on the right governance mechanisms has been a slow process, partly because industry, academia, and NGOs are not certain what the solutions are yet.
If AI safety is still far from a top-tier priority for most senior policymakers around the world, and the steps they would need to take to address it are still unclear, this may change as AI’s capabilities become more impressive, and its risks become more salient. The release of Cicero – Meta’s Diplomacy-winning trickster – was a small example of that: Last year, many would have laughed at the idea of an AI system deceiving or manipulating a human. Now there’s something to point to.
Conclusion
The rapid development of new AI techniques, especially deep learning, is producing impressive breakthroughs at a fast pace. We may be advancing so quickly that we are now at a crucial point where decisions we make have important effects on the future of humanity over the next century or more. And there is a real risk that understanding and controlling advanced AIs could become very difficult very quickly, and be difficult to fix after that point.
AI safety research focuses on avoiding these types of scenarios by making sure that if we do ever create an AGI or something close to it, we can do so with safeguards that avoid the risks outlined above. Very little of the work on AI safety involves actively slowing progress down, or stopping us from getting useful new tools – as, say, the focus on safety above all else in nuclear power arguably has. Basic safety measures in aviation and motoring are probably well worth the costs they have involved – by the same token, there does not need to be a significant trade-off between AI safety and technological progress.
In a paper about large language models, researchers from Open AI wrote that ‘we are, in a sense, building the plane as it is taking off’. This arguably also applies to the field as a whole. Artificial general intelligence is a worthwhile and important goal: Getting it right will lead to enormous breakthroughs in science, research, welfare, and how we live our lives. But the way we get there matters.